
 1 week ago
1 week ago
ARTICLE AD BOX
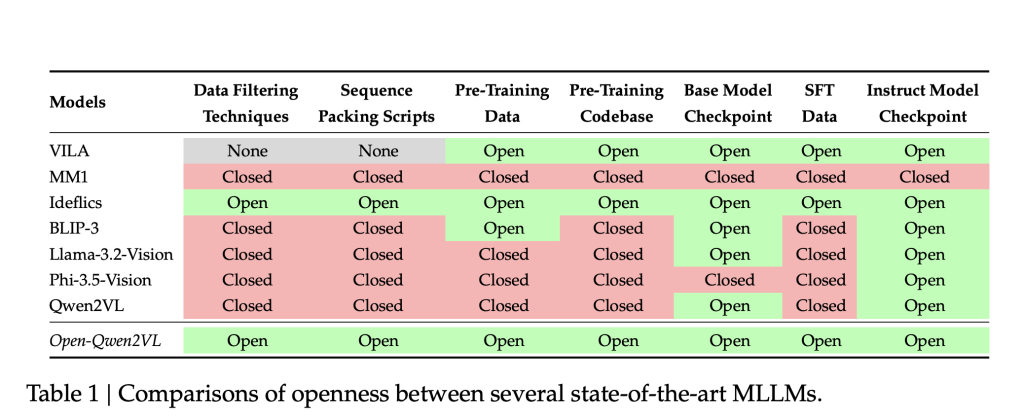
Multimodal Large Language Models (MLLMs) person precocious nan integration of ocular and textual modalities, enabling advancement successful tasks specified arsenic image captioning, ocular mobility answering, and archive interpretation. However, nan replication and further improvement of these models are often hindered by a deficiency of transparency. Many state-of-the-art MLLMs do not merchandise cardinal components, including training code, information curation methodologies, and pretraining datasets. Furthermore, nan important computational resources required for training these models airs a important barrier, peculiarly for world researchers pinch constricted infrastructure. This deficiency of accessibility impedes reproducibility and slows nan dissemination of caller techniques wrong nan investigation community.
Researchers from UC Santa Barbara, Bytedance and NVIDIA present Open-Qwen2VL, a 2-billion parameter Multimodal Large Language Model that has been pre-trained connected 29 cardinal image-text pairs utilizing astir 220 A100-40G GPU hours. Developed collaboratively by researchers from UC Santa Barbara, ByteDance, and Nvidia Research, Open-Qwen2VL is designed to reside reproducibility and assets constraints successful MLLM research. The task provides a complete suite of open-source resources, including nan training codebase, information filtering scripts, WebDataset-formatted pretraining data, and some guidelines and instruction-tuned exemplary checkpoints. This broad merchandise intends to support transparent experimentation and method improvement successful nan multimodal learning domain.
Open-Qwen2VL is based connected nan Qwen2.5-1.5B-Instruct LLM backbone, coupled pinch a SigLIP-SO-400M imagination encoder. An Adaptive Average-Pooling Visual Projector reduces nan number of ocular tokens from 729 to 144 during pretraining, which improves computational efficiency. The token count is accrued backmost to 729 during nan supervised fine-tuning (SFT) stage. This low-to-high solution strategy maintains image knowing capabilities while optimizing for assets usage.
To further heighten training efficiency, Open-Qwen2VL implements multimodal series packing, allowing nan concatenation of aggregate image-text pairs into sequences of astir 4096 tokens, thereby minimizing padding and computational overhead. The imagination encoder parameters stay stiff during pretraining to conserve resources and are optionally unfrozen during SFT to amended downstream performance.
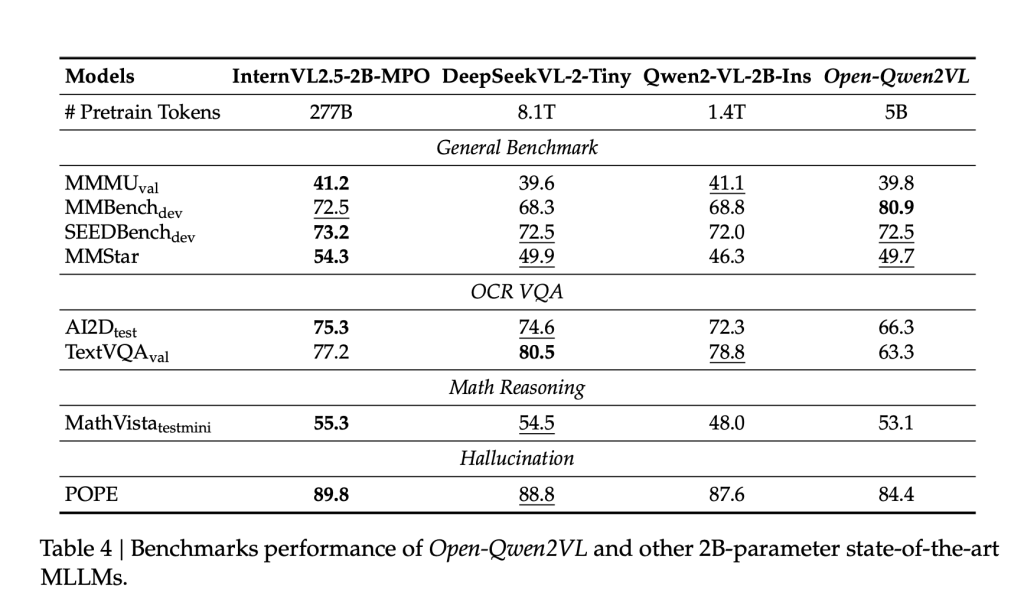
Open-Qwen2VL is trained connected only 0.36% of nan token count utilized successful Qwen2-VL, yet demonstrates comparable aliases superior capacity crossed respective benchmarks. The exemplary achieves a people of 80.9 connected MMBench, and performs competitively connected SEEDBench (72.5), MMStar (49.7), and MathVista (53.1). Ablation studies bespeak that integrating a mini subset (5M samples) of high-quality image-text pairs filtered utilizing MLM-based techniques tin consequence successful measurable capacity improvements, highlighting nan value of information value complete volume.
In addition, Open-Qwen2VL exhibits robust few-shot multimodal in-context learning capabilities. When evaluated connected datasets specified arsenic GQA and TextVQA, nan exemplary shows 3% to 12% accuracy gains from 0-shot to 8-shot scenarios. Fine-tuning capacity scales predictably pinch nan size of nan instruction tuning dataset, pinch capacity gains plateauing astir 8M examples from nan MAmmoTH-VL-10M dataset.
Open-Qwen2VL introduces a reproducible and resource-efficient pipeline for training multimodal ample connection models. By systematically addressing nan limitations of anterior models successful position of openness and compute requirements, it enables broader information successful MLLM research. The model’s creation choices—including businesslike ocular token handling, multimodal series packing, and judicious information selection—illustrate a viable way guardant for world institutions aiming to lend to nan field. Open-Qwen2VL establishes a reproducible baseline and provides a instauration for early activity connected scalable, high-performance MLLMs wrong constrained computational environments.
Check out the Paper, Model, Data and Code. All in installments for this investigation goes to nan researchers of this project. Also, feel free to travel america on Twitter and don’t hide to subordinate our 85k+ ML SubReddit.
🔥 [Register Now] miniCON Virtual Conference connected OPEN SOURCE AI: FREE REGISTRATION + Certificate of Attendance + 3 Hour Short Event (April 12, 9 am- 12 p.m. PST) + Hands connected Workshop [Sponsored]

Asif Razzaq is nan CEO of Marktechpost Media Inc.. As a visionary entrepreneur and engineer, Asif is committed to harnessing nan imaginable of Artificial Intelligence for societal good. His astir caller endeavor is nan motorboat of an Artificial Intelligence Media Platform, Marktechpost, which stands retired for its in-depth sum of instrumentality learning and heavy learning news that is some technically sound and easy understandable by a wide audience. The level boasts of complete 2 cardinal monthly views, illustrating its fame among audiences.

: A Large Language Model Optimized For Diagnostic Reasoning, And Evaluate Its Ability To Generate A Differential Diagnosis")
 Recommendation System With Pytorch")





 Launches Olmotrace: Real-time Tracing Of Llm Outputs Back To Training Data")
") English (US) ·
English (US) · ") Indonesian (ID) ·
Indonesian (ID) ·