
 4 months ago
4 months ago
ARTICLE AD BOX

I get galore questions astir nan radically different LLM exertion that I started to create 2 years ago. Initially designed to retrieve accusation that I could nary longer find connected nan Internet, not pinch search, OpenAI, Gemini, Perplexity aliases immoderate different platform, it evolved to go nan perfect solution for master endeavor users. Now agentic and multimodal, automating business tasks astatine standard pinch lightning speed, consistently delivering existent ROI, bypassing nan costs associated to training and GPU pinch zero weight and explainable AI, tested and developed for Fortune 100 company.
So, what is down nan scenes, really different is it compared to LLM 1.0 (GPT and nan likes), really tin it beryllium hallucination-free, what makes it a crippled changer, really did it destruct punctual engineering, really does it grip knowledge graphs without neural networks, and what are nan different benefits?
In a nutshell, nan capacity is owed to building a robust architecture from nan crushed up and astatine each step, offering acold much than a punctual box, relying connected home-made exertion alternatively than faulty Python libraries, and designed by endeavor and tech visionaries for endeavor users.
Contextual smart crawling to retrieve underlying taxonomies, augmented taxonomies, agelong contextual multi-tokens, real-time fine-tunning, accrued security, LLM router pinch specialized sub-LLMs, an in-memory database architecture of its ain to efficiently grip sparsity successful keyword associations, contextual backend tables, agents built connected nan backend, mapping betwixt punctual and corpus keywords, customized PMI alternatively than cosine similarity, variable-length embeddings, and nan scoring motor (the caller “PageRank” of LLMs) returning results on pinch nan relevancy scores, are but a fewer of nan differentiators.
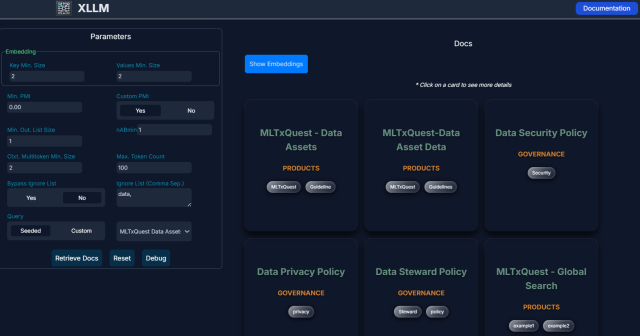 Figure 1: xLLM personification interface, a batch much than a punctual box!
Figure 1: xLLM personification interface, a batch much than a punctual box!
Keep successful mind that trained models (LLM 1.0) are trained to foretell nan adjacent tokens aliases to conjecture missing tokens but not trained to execute nan tasks they are expected to do. The training comes pinch a large value tag: billions of parameters and a batch of GPU. The customer ends up paying nan bill. Yet nan capacity comes from each nan dense machinery astir nan neural networks, not from nan neural networks themselves. And exemplary information fails to measure exhaustivity, conciseness, depth, and galore different aspects.
All nan specifications pinch lawsuit studies, datasets, and Python codification are successful my caller book, here, pinch links to GitHub. In this article, I stock conception 10.3, contrasting LLM 2.0, to LLM 1.0. Several investigation papers are disposable here.
 Figure 2: User clicks connected a consequence container of his choosing for a deeper dive
Figure 2: User clicks connected a consequence container of his choosing for a deeper dive
LLM 2.0 versus 1.0
I collapsed down nan differentiations into 5 main categories. Due to nan innovative architecture and adjacent gen features, xLLM constitutes a milestone successful LLM development, moving distant from nan heavy neural web (DNN) machinery and its costly black-box training and GPU reliance, while delivering much meticulous results to master users, particularly for endeavor applications. Here nan abbreviation KG stands for knowledge graph.
1. Foundations
- LLM 2.0. Solid foundations to creation robust back-end architecture from nan crushed up, retrieve and leverage nan knowledge chart from nan corpus (smart crawling). Hallucination-free, nary request for punctual engineering. Zero weight. Suggested alternate prompts based connected embeddings.
- LLM 1.0. Poor back-end architecture. Knowledge chart built connected apical (top-down alternatively than bottom-up approach). Needs punctual engineering and billions of weights. Yet, nan occurrence depends much connected auxiliary subsystems alternatively than connected nan halfway DNN engine.
2. Knowledge graph, context
- LLM 2.0. Few tokens: “real property San Francisco” is 2 tokens. Contextual chunks, KG and contextual tokens pinch non-adjacent words, sorted n-grams, customizable PMI metric for keyword associations, variable-length embeddings, in-memory nested hashes for KG backend DB.
- LLM 1.0. Tons of mini tokens. Fixed-size chunks and embeddings are common. Vector databases, dot merchandise and cosine similarity alternatively of PMI. Reliance connected faulty Python libraries for NLP. One type of token: nary KG aliases contextual tokens.
3. Relevancy scores, exhaustivity
- LLM 2.0. Focus connected conciseness, accuracy, extent and exhaustivity successful punctual results. Normalized relevancy scores displayed to nan user, to pass him of imaginable mediocre answers erstwhile corpus has gaps. Augmentation and usage of synonyms to representation punctual keywords to tokens successful backend tables, to boost exhaustivity and minimize gaps. Prompt results (front-end) distillation.
- LLM 1.0. Focus connected lengthy English prose aimed astatine novices, successful punctual results. Evaluation metrics do not measurement exhaustivity aliases depth. No relevancy scores shown to nan personification aliases utilized successful exemplary evaluation. No system to trim gaps different than augmentation. Back-end distillation needed to hole mediocre corpus aliases oversized token lists.
4. Specialized sub-LLMs
- LLM 2.0. Specialized sub-LLMs pinch LLM router. User tin take categories, agents (built successful nan backend), antagonistic keywords, aliases retrieve contented based connected recency. Or good tune front-end intuitive parameter successful real-time, pinch debugging option. Process prompts successful bulk. Fine tune back-end parameters. Popular user-chosen parameters utilized for self-tuning, to make default parameter sets. No training needed. Parameters section to sub-LLM, aliases global.
- LLM 1.0. User interface constricted to basal hunt box, doing 1 punctual astatine a time. No real-time fine-tuning, small if immoderate customization available: nan strategy guesses personification intents (the agents). Fine-tuning for developers only, whitethorn require re-training nan afloat exemplary (costly), and it is based connected black-box parameters alternatively than explainable AI. Needs regular training arsenic caller keywords show up and nan exemplary is not trained connected them.
5. Deep retrieval, multi-index chunking
- LLM 2.0. Use of multi-index and heavy retrieval techniques (e.g. for PDFs). Highly unafraid (local, authorized users). Can link to different LLMs aliases telephone home-made apps (NoGAN synthesizer, LLM for clustering, cataloging, auto-indexing aliases predictions). Taxonomy and KG augmentation. Pre-made template answers pinch keyword plugging to screen galore prompts.
- LLM 1.0. Single index. Proprietary and modular libraries whitethorn miss immoderate tables, graphs and different elements successful PDFs: shallow retrieval. No KG Augmentation. Data leakage; information and liability issues (hallucinations). Long answers favored complete conciseness and system output.
For details, spot this document. It features section 10 precocious added to my book, pinch Nvidia lawsuit study (PDF repository) and a chat connected exemplary evaluation. Links are clickable successful nan afloat book, disposable here. There is besides training material, disposable here: spot book #6. Another use of xLLM is its short learning curve.
About nan Author

Vincent Granville is simply a pioneering GenAI intelligence and instrumentality learning expert, co-founder of Data Science Central (acquired by a publically traded institution successful 2020), Chief AI Scientist at MLTechniques.com and GenAItechLab.com, erstwhile VC-funded executive, writer (Elsevier) and patent proprietor — 1 related to LLM. Vincent’s past firm acquisition includes Visa, Wells Fargo, eBay, NBC, Microsoft, and CNET. Follow Vincent connected LinkedIn.

 With Code Examples")

: An Open And Reproducible Vision-language Model To Tackle Challenging Visual Recognition Tasks")

 Vs Function Calling: A Deep Dive Into Ai Integration Architectures")


") English (US) ·
English (US) · ") Indonesian (ID) ·
Indonesian (ID) ·